React-Fiber
React Fiber
React16 以上的版本中引入了 Fiber 架构
Fiber 设计思想
Fiber 是对 React 核心算法的重构,facebook 团队使用两年多的时间去重构 React 的核心算法,在React16 以上的版本中引入了 Fiber 架构,其中的设计思想是非常值得我们学习的。
为什么需要 Fiber
我们知道,在浏览器中,页面是一帧一帧绘制出来的,渲染的帧率与设备的刷新率保持一致。一般情况下,设备的屏幕刷新率为 1s 60 次,当每秒内绘制的帧数(FPS)超过 60 时,页面渲染是流畅的;而当 FPS 小于 60 时,会出现一定程度的卡顿现象。下面来看完整的一帧中,具体做了哪些事情:

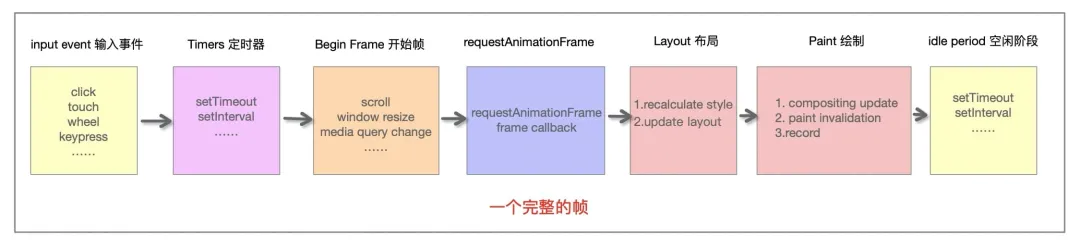
- 首先需要处理输入事件,能够让用户得到最早的反馈
- 接下来是处理定时器,需要检查定时器是否到时间,并执行对应的回调
- 接下来处理
Begin Frame(开始帧),即每一帧的事件,包括window.resize、scroll、media query change等 - 接下来执行请求动画帧
requestAnimationFrame(rAF),即在每次绘制之前,会执行 rAF 回调 - 紧接着进行
Layout操作,包括计算布局和更新布局,即这个元素的样式是怎样的,它应该在页面如何展示 - 接着进行 Paint 操作,得到树中每个节点的尺寸与位置等信息,浏览器针对每个元素进行内容填充
- 到这时以上的六个阶段都已经完成了,接下来处于空闲阶段(Idle Peroid),可以在这时执行
requestIdleCallback里注册的任务(后面会详细讲到这个requestIdleCallback,它是 React Fiber 实现的基础)
js 引擎和页面渲染引擎是在同一个渲染线程之内,两者是互斥关系。如果在某个阶段执行任务特别长,例如在定时器阶段或Begin Frame阶段执行时间非常长,时间已经明显超过了 16ms,那么就会阻塞页面的渲染,从而出现卡顿现象。
在 react16 引入 Fiber 架构之前,react 会采用递归对比虚拟 DOM 树,找出需要变动的节点,然后同步更新它们,这个过程 react 称为 reconcilation(协调)。在reconcilation期间,react 会一直占用浏览器资源,会导致用户触发的事件得不到响应。实现的原理如下所示:
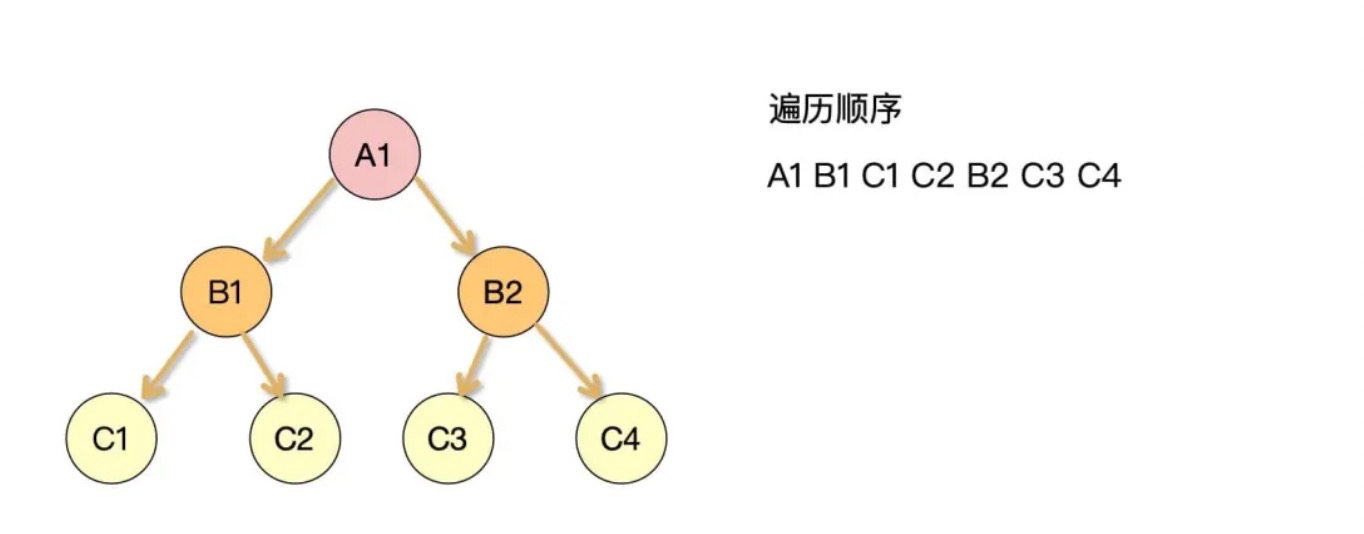
这里有 7 个节点,B1、B2 是 A1 的子节点,C1、C2 是 B1 的子节点,C3、C4 是 B2 的子节点。传统的做法就是采用深度优先遍历去遍历节点,具体代码如下:
1 | |
打印:
1 | |
这种遍历是递归调用,执行栈会越来越深,而且不能中断,中断后就不能恢复了。递归如果非常深,就会十分卡顿。如果递归花了 100ms,则这 100ms 浏览器是无法响应的,代码执行时间越长卡顿越明显。传统的方法存在不能中断和执行栈太深的问题。
因此,为了解决以上的痛点问题,React 希望能够彻底解决主线程长时间占用问题,于是引入了 Fiber 来改变这种不可控的现状,把渲染/更新过程拆分为一个个小块的任务,通过合理的调度机制来调控时间,指定任务执行的时机,从而降低页面卡顿的概率,提升页面交互体验。通过 Fiber 架构,让reconcilation过程变得可被中断。适时地让出 CPU 执行权,可以让浏览器及时地响应用户的交互。
React16 中使用了 Fiber,但是 Vue 是没有 Fiber 的,为什么呢?原因是二者的优化思路不一样:
- Vue 是基于
template和watcher的组件级更新,把每个更新任务分割得足够小,不需要使用到 Fiber 架构,将任务进行更细粒度的拆分 - React 是不管在哪里调用
setState,都是从根节点开始更新的,更新任务还是很大,需要使用到 Fiber 将大任务分割为多个小任务,可以中断和恢复,不阻塞主进程执行高优先级的任务
下面,让我们走进 Fiber 的世界,看看具体是怎么实现的。
什么是 Fiber
Fiber 可以理解为是一个执行单元,也可以理解为是一种数据结构。
一个执行单元
Fiber 可以理解为一个执行单元,每次执行完一个执行单元,react 就会检查现在还剩多少时间,如果没有时间则将控制权让出去。React Fiber 与浏览器的核心交互流程如下:
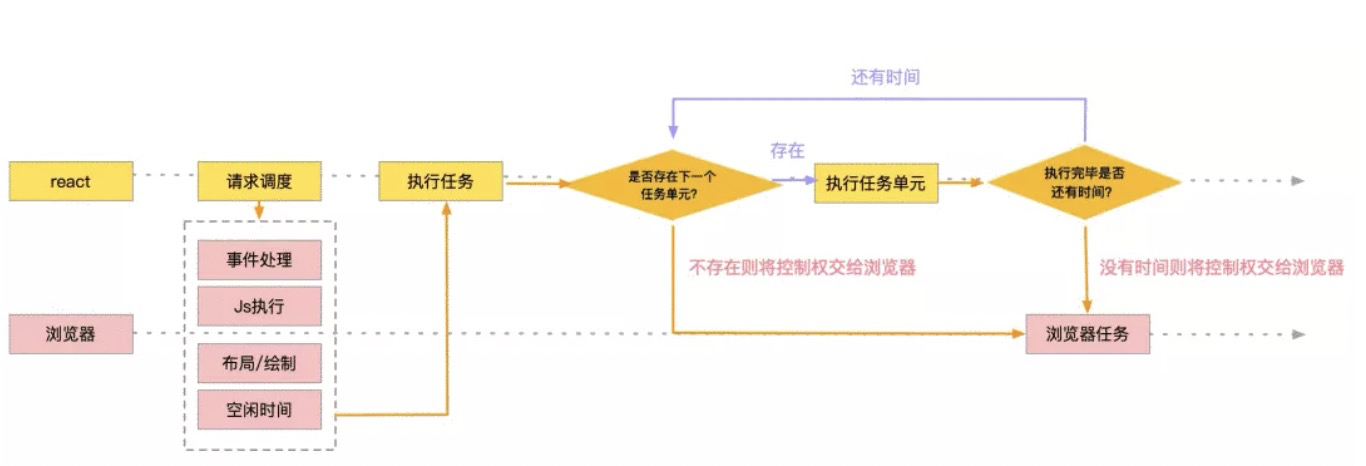
首先 React 向浏览器请求调度,浏览器在一帧中如果还有空闲时间,会去判断是否存在待执行任务,不存在就直接将控制权交给浏览器,如果存在就会执行对应的任务,执行完成后会判断是否还有时间,有时间且有待执行任务则会继续执行下一个任务,否则就会将控制权交给浏览器。这里会有点绕,可以结合上述的图进行理解。
Fiber 可以被理解为划分一个个更小的执行单元,它是把一个大任务拆分为了很多个小块任务,一个小块任务的执行必须是一次完成的,不能出现暂停,但是一个小块任务执行完后可以移交控制权给浏览器去响应用户,从而不用像之前一样要等那个大任务一直执行完成再去响应用户。
一种数据结构
Fiber 还可以理解为是一种数据结构,React Fiber 就是采用链表实现的。每个 Virtual DOM 都可以表示为一个 fiber,如下图所示,每个节点都是一个 fiber。一个 fiber 包括了 child(第一个子节点)、sibling(兄弟节点)、return(父节点)等属性,React Fiber 机制的实现,就是依赖于以下的数据结构。在下文中会讲到基于这个链表结构,Fiber 究竟是如何实现的。
PS:这里需要说明一下,Fiber 是 React 进行重构的核心算法,fiber 是指数据结构中的每一个节点,如下图所示的 A1、B1 都是一个 fiber。

requestAnimationFrame
在 Fiber 中使用到了requestAnimationFrame,它是浏览器提供的绘制动画的 api 。它要求浏览器在下次重绘之前(即下一帧)调用指定的回调函数更新动画。
例如我想让浏览器在每一帧中,将页面 div 元素的宽变长 1px,直到宽度达到 100px 停止,这时就可以采用requestAnimationFrame来实现这个功能。
1 | |
浏览器会在每一帧中,将 div 的宽度变宽 1px,知道到达 100px 为止。打印出每一帧的时间间隔如下,大约是 16ms 左右。
requestIdleCallback
requestIdleCallback 也是 react Fiber 实现的基础 api 。我们希望能够快速响应用户,让用户觉得够快,不能阻塞用户的交互,requestIdleCallback能使开发者在主事件循环上执行后台和低优先级的工作,而不影响延迟关键事件,如动画和输入响应。正常帧任务完成后没超过 16ms,说明有多余的空闲时间,此时就会执行requestIdleCallback里注册的任务。
具体的执行流程如下,开发者采用requestIdleCallback方法注册对应的任务,告诉浏览器我的这个任务优先级不高,如果每一帧内存在空闲时间,就可以执行注册的这个任务。另外,开发者是可以传入timeout参数去定义超时时间的,如果到了超时时间了,浏览器必须立即执行,使用方法如下:window.requestIdleCallback(callback, { timeout: 1000 })。浏览器执行完这个方法后,如果没有剩余时间了,或者已经没有下一个可执行的任务了,React 应该归还控制权,并同样使用requestIdleCallback去申请下一个时间片。具体的流程如下图:
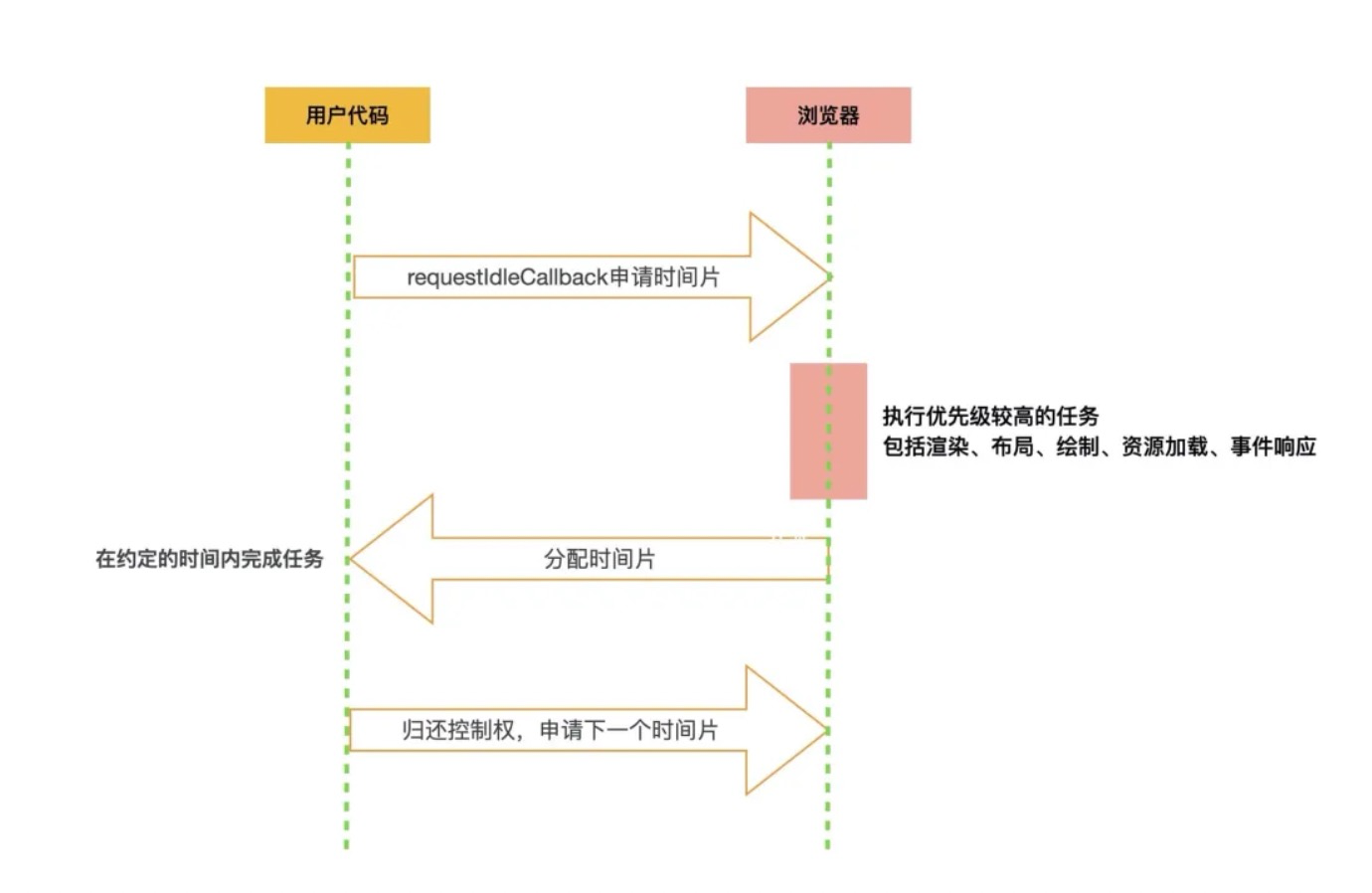
window.requestIdleCallback(callback)的callback中会接收到默认参数 deadline ,其中包含了以下两个属性:
timeRamining返回当前帧还剩多少时间供用户使用didTimeout返回 callback 任务是否超时
requestIdleCallback 方法非常重要,下面分别讲两个例子来理解这个方法,在每个例子中都需要执行多个任务,但是任务的执行时间是不一样的,下面来看浏览器是如何分配时间执行这些任务的:
一帧执行
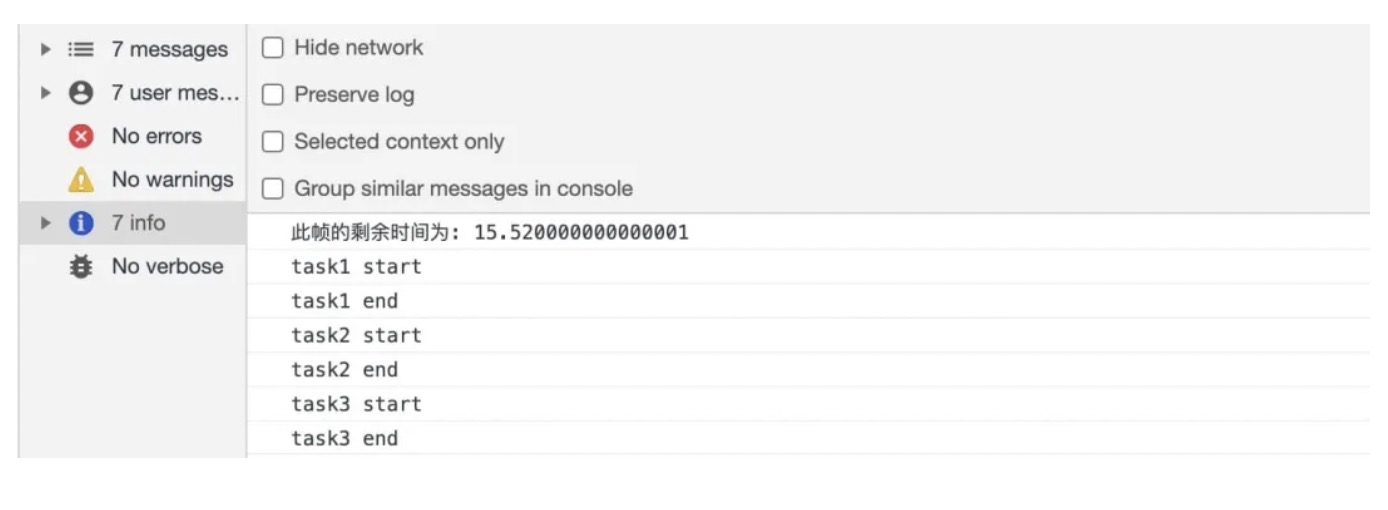
直接执行 task1、task2、task3,各任务的时间均小于 16ms:
1 | |
上面定义了一个任务队列taskQueue,并定义了workloop函数,其中采用window.requestIdleCallback(workloop, { timeout: 1000 })去执行taskQueue中的任务。每个任务中仅仅做了 console.log 的工作,时间是非常短的,浏览器计算此帧中还剩余 15.52ms,足以一次执行完这三个任务,因此在此帧的空闲时间中,taskQueue 中定义的三个任务均执行完毕。打印结果如下:
多帧执行
在 task1、task2、task3 中加入睡眠时间,各自执行时间超过 16ms:
1 | |
基于以上的例子做了部分改造,让taskQueue中的每个任务的执行时间都超过 16.6ms,看打印结果知道浏览器第一帧的空闲时间为 14ms,只能执行一个任务,同理,在第二帧、第三帧的时间也只够执行一个任务。所有这三个任务分别是在三帧中分别完成的。打印结果如下:
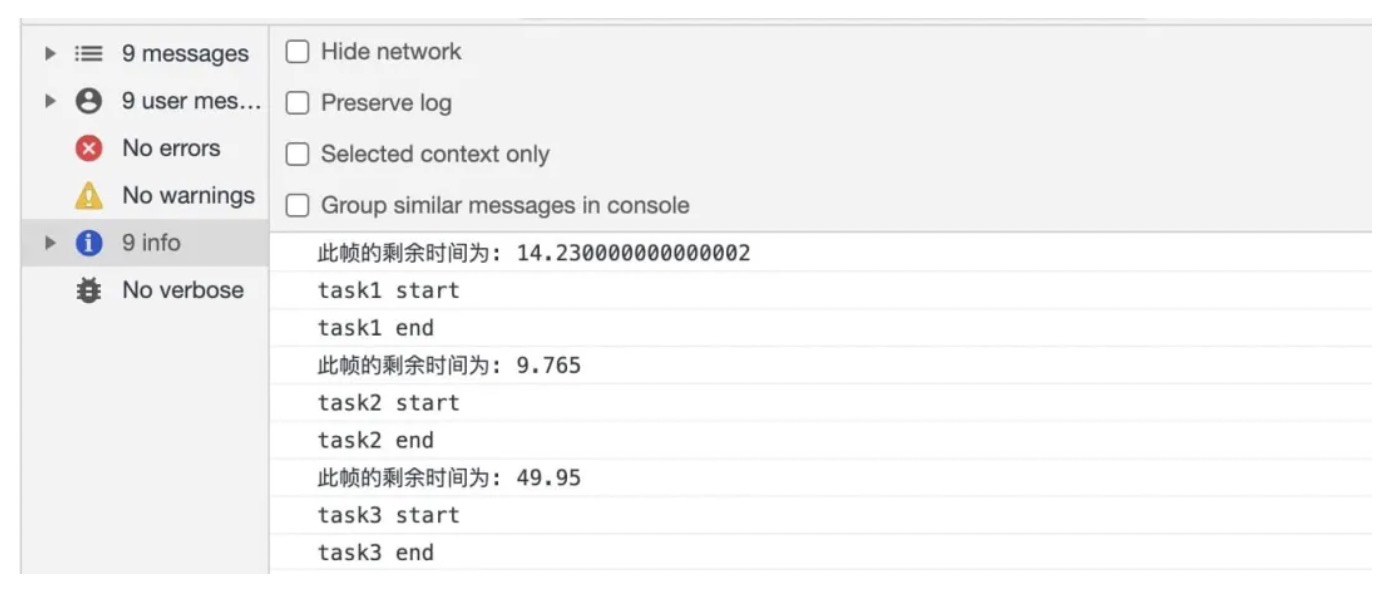
浏览器一帧的时间并不严格是 16ms,是可以动态控制的(如第三帧剩余时间为 49.95ms)。如果子任务的时间超过了一帧的剩余时间,则会一直卡在这里执行,直到子任务执行完毕。如果代码存在死循环,则浏览器会卡死。如果此帧的剩余时间大于 0(有空闲时间)或者已经超时(上文定义了 timeout 时间为 1000,必须强制执行了),且当时存在任务,则直接执行该任务。如果没有剩余时间,则应该放弃执行任务控制权,把执行权交还给浏览器。如果多个任务执行总时间小于空闲时间的话,是可以在一帧内执行多个任务的。
Fiber 链表结构设计
Fiber 结构是使用链表实现的,Fiber tree实际上是个单链表树结构,详见 ReactFiber.js 源码,在这里我们看看 Fiber 的链表结构是怎样的,了解了这个链表结构后,能更快地理解后续 Fiber 的遍历过程。
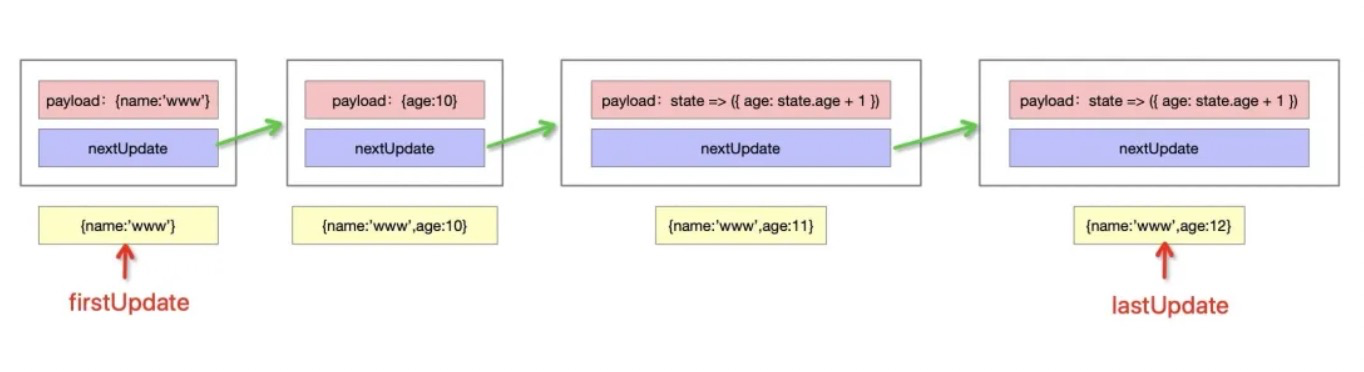
以上每一个单元包含了payload(数据)和nextUpdate(指向下一个单元的指针),定义结构如下:
1 | |
接下来定义一个队列,把每个单元串联起来,其中定义了两个指针:头指针firstUpdate和尾指针lastUpdate,作用是指向第一个单元和最后一个单元,并加入了baseState属性存储 React 中的 state 状态。如下所示:
1 | |
接下来定义两个方法:插入节点单元(enqueueUpdate)、更新队列(forceUpdate)。插入节点单元时需要考虑是否已经存在节点,如果不存在直接将firstUpdate、lastUpdate指向此节点即可。更新队列是遍历这个链表,根据payload中的内容去更新 state 的值。
1 | |
最后写一个 demo,实例化一个队列,向其中加入很多节点,再更新这个队列:
1 | |
打印结果如下:
1 | |
Fiber 节点设计
Fiber 的拆分单位是 fiber(fiber tree上的一个节点),实际上就是按虚拟 DOM 节点拆,我们需要根据虚拟 dom 去生成 Fiber 树。下文中我们把每一个节点叫做 fiber 。fiber 节点结构如下,源码详见 ReactInternalTypes.js。
1 | |
fiber 节点包括了以下的属性:
(1)type & key
- fiber 的 type 和 key 与 React 元素的作用相同。fiber 的 type 描述了它对应的组件,对于复合组件,type 是函数或类组件本身。对于原生标签(div,span 等),type 是一个字符串。随着 type 的不同,在 reconciliation 期间使用 key 来确定 fiber 是否可以重新使用。
(2)stateNode
- stateNode 保存对组件的类实例,DOM 节点或与 fiber 节点关联的其他 React 元素类型的引用。一般来说,可以认为这个属性用于保存与 fiber 相关的本地状态。
(3)child & sibling & return
- child 属性指向此节点的第一个子节点(大儿子)。
- sibling 属性指向此节点的下一个兄弟节点(大儿子指向二儿子、二儿子指向三儿子)。
- return 属性指向此节点的父节点,即当前节点处理完毕后,应该向谁提交自己的成果。如果 fiber 具有多个子 fiber,则每个子 fiber 的 return fiber 是 parent 。
(4)alternate - 靠这个属性,在 Fiber 双缓存的时候,到达另外一个 Fiber tree
- 当前屏幕上显示的 Fiber 树叫做 current Fiber Tree,正在内存中构建的 Fiber 树叫做 workInProgress Fiber Tree
1 | |
所有 fiber 节点都通过以下属性:child,sibling 和 return 来构成一个 fiber node 的 linked list(后面我们称之为链表)。如下图所示:
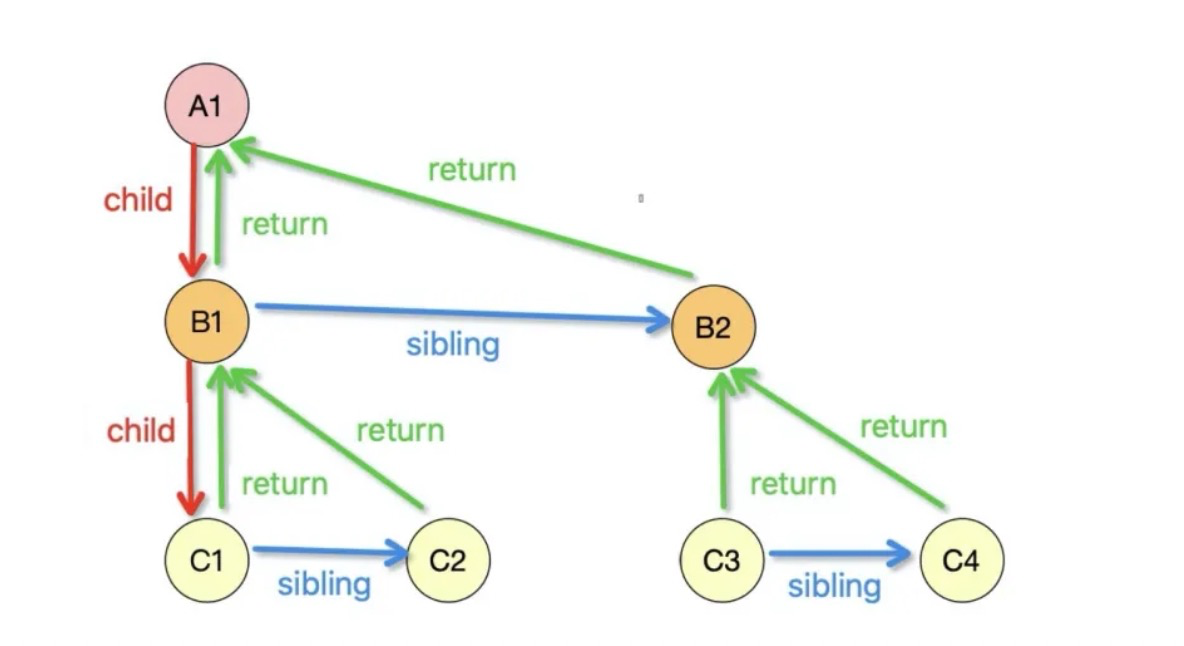
其他的属性还有memoizedState(创建输出的 fiber 的状态)、pendingProps(将要改变的 props )、memoizedProps(上次渲染创建输出的 props )、pendingWorkPriority(定义 fiber 工作优先级)等等,在这里就不展开描述了。
Fiber 执行原理
从根节点开始渲染和调度的过程可以分为两个阶段:render 阶段、commit 阶段。
- render 阶段:这个阶段是可中断的,会找出所有节点的变更
- commit 阶段:这个阶段是不可中断的,会执行所有的变更
render 阶段
此阶段会找出所有节点的变更,如节点新增、删除、属性变更等,这些变更 react 统称为副作用(effect),此阶段会构建一棵Fiber tree,以虚拟 dom 节点为维度对任务进行拆分,即一个虚拟 dom 节点对应一个任务,最后产出的结果是effect list,从中可以知道哪些节点更新、哪些节点增加、哪些节点删除了。
遍历流程
React Fiber首先是将虚拟 DOM 树转化为Fiber tree,因此每个节点都有child、sibling、return属性,遍历Fiber tree时采用的是后序遍历方法:
- 从顶点开始遍历
- 如果有大儿子,先遍历大儿子;如果没有大儿子,则表示遍历完成
- 大儿子:a. 如果有弟弟,则返回弟弟,跳到 2b. 如果没有弟弟,则返回父节点,并标志完成父节点遍历,跳到 2d. 如果没有父节点则标志遍历结束

定义树结构:
1 | |
写遍历方法:
1 | |
打印结果:
1 | |
收集 effect list
知道了遍历方法之后,接下来需要做的工作就是在遍历过程中,收集所有节点的变更产出effect list,注意其中只包含了需要变更的节点。通过每个节点更新结束时向上归并effect list来收集任务结果,最后根节点的effect list里就记录了包括了所有需要变更的结果。
收集effect list的具体步骤为:
- 如果当前节点需要更新,则打
tag更新当前节点状态(props, state, context 等) - 为每个子节点创建 fiber。如果没有产生
child fiber,则结束该节点,把effect list归并到return,把此节点的sibling节点作为下一个遍历节点;否则把child节点作为下一个遍历节点 - 如果有剩余时间,则开始下一个节点,否则等下一次主线程空闲再开始下一个节点
- 如果没有下一个节点了,进入
pendingCommit状态,此时effect list收集完毕,结束。
收集effect list的遍历顺序如下所示:
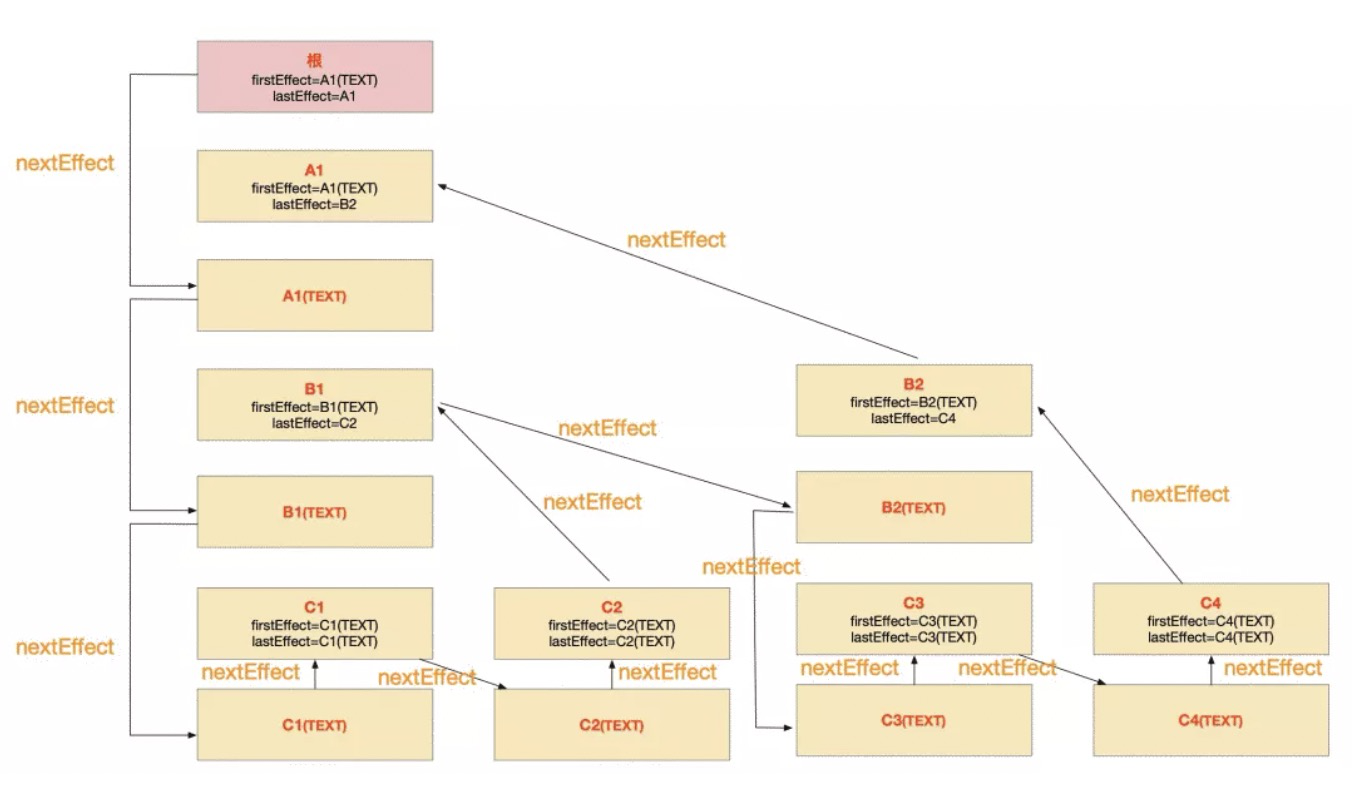
遍历子虚拟 DOM 元素数组,为每个虚拟 DOM 元素创建子 fiber:
1 | |
定义一个方法收集此 fiber 节点下所有的副作用,并组成effect list。注意每个 fiber 有两个属性:
- firstEffect:指向第一个有副作用的子 fiber
- lastEffect:指向最后一个有副作用的子 fiber
中间的使用nextEffect做成一个单链表。
1 | |
接下来定义一个递归函数,从根节点出发,把全部的 fiber 节点遍历一遍,产出最终全部的effect list:
1 | |
commit 阶段
commit 阶段需要将上阶段计算出来的需要处理的副作用一次性执行,此阶段不能暂停,否则会出现 UI 更新不连续的现象。此阶段需要根据effect list,将所有更新都 commit 到 DOM 树上。
根据一个 fiber 的 effect list 更新视图
根据一个 fiber 的effect list列表去更新视图(这里只列举了新增节点、删除节点、更新节点的三种操作):
1 | |
根据全部 fiber 的 effect list 更新视图
写一个递归函数,从根节点出发,根据effect list完成全部更新:
1 | |
完成视图更新
接下来定义循环执行工作,当计算完成每个 fiber 的effect list后,调用 commitRoot 完成视图更新:
1 | |
到这时,已经根据收集到的变更信息,完成了视图的刷新操作
学习文章:https://mp.weixin.qq.com/s/uYd72aUb9wvUcjICFLREgg
感谢阅读,勘误、纠错或其他请联系progerchai@gmail.com,或者点击这里提 issue 给我
欢迎交流 👏,你的每一次指导都可以让我进步
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!